Simple Quant Labs
Last edit: 2025.04.20
고전적 시계열 분해 (Classical Time Series Decomposition)
"시계열 분해"의 목적이 뭘까요? 현실 세계의 시계열 데이터(예: 주가, 환율, 기온, 판매량 등)는 단순한 랜덤 패턴이 아니라 복잡한 구조적 패턴을 가지고 있습니다. 이 데이터들을 분석하거나 예측하려면:
- 시간이 지남에 따라 전반적으로 상승하거나 하락하는 추세가 있는지
- 반복되는 계절성 패턴이 있는지 (예: 여름에 에어컨 판매량 증가)
- 그 외 예측 불가능한 불규칙 요인(노이즈)이 있는지
시점 \( t \)에서 관측된 시계열 \( y_t \)를 다음과 같이 분해할 수 있습니다:
$$ y_t = T_t + S_t + R_t \quad \text{(1)} $$ $$ y_t = T_t \times S_t \times R_t \quad \text{(2)} $$
여기서 \( T_t \)는 추세 성분 (Trend), \( S_t \)는 계절 성분 (Seasonality), \( R_t \)는 잔차 (Residual)입니다. (1)은 가법 모형이며, 계절성이 일정할 때 적합합니다. (2)는 승법 모형이며, 계절성이 추세에 따라 달라지는 경우 사용합니다. 예를 들어, 수익률, 이자율, 환율과 같은 재무 시계열은 주로 승법 분해가 적합합니다.
승법 모형에 로그를 취하면 다음과 같이 가법 모형으로 변환할 수 있습니다:
$$ \log y_t = \log T_t + \log S_t + \log R_t $$
1️⃣ 추세 성분 \( T_t \) 추정 (Moving Average)
계절 주기를 \( m \)이라 할 때, 추세는 다음과 같이 이동 평균으로 추정합니다.
- 홀수 \( m \): $$ T_t = \frac{1}{m} \sum_{j=-(m-1)/2}^{(m-1)/2} y_{t+j} $$ → 즉, 현재 시점을 중심으로 앞뒤로 대칭적인 m개의 관측값을 평균 내어 T_t를 계산하는 방식입니다. 이를 window 크기가 m인 단순 이동 평균 (MA) 라고 합니다.
- 짝수 \( m \): $$ T_t = \frac{1}{2} \left( \frac{1}{m} \sum_{j=-m/2}^{m/2 - 1} y_{t+j} + \frac{1}{m} \sum_{j=-m/2+1}^{m/2} y_{t+j} \right) $$ → 짝수 개의 관측값을 기준으로는 중심이 딱 떨이지지 않기 때문에, 두 개의 평균을 구한 뒤, 그 중간값을 취해서 \( T_t \)를 계산합니다. 이를 window 크기가 m인 중심 이동평균 (centered MA) 라고 합니다.
이렇게 정의된 이동평균은 계절성의 주기만큼 평균을 취하기 때문에, 결과적으로 계절성을 제거하는 효과를 가집니다 (즉, 계절성을 제거함으로써 추세 성분 \( T_t \)를 분리할 수 있습니다).
2️⃣ 계절 성분 \( S_t \) 추정
추정된 \( T_t \)로부터 다음과 같이 계절 성분을 계산합니다.
- 가법 모형: \( y_t - T_t \)
- 승법 모형: \( \frac{y_t}{T_t} \)
예: 월별 seasonality의 경우, 각 월별 평균을 구해 계절 성분 \( S_t \)를 추정합니다.
3️⃣ 잔차 \( R_t \) 추정
- 가법 모형: \( R_t = y_t - T_t - S_t \)
- 승법 모형: \( R_t = \frac{y_t}{T_t S_t} \)
고전적 분해는 직관적이지만, 이동 평균은 이상치에 민감하고 \( S_t \)는 동적인 계절성 반영이 어렵다는 한계가 있습니다.
실습: Bitcoin 가격 분해 예제
이제 아래는 yahoo finance, pandas와 statsmodels를 이용한 비트코인 가격 정보를 download해서 moving average로 구한 단기 및 장기 추세선을 구해보고 시계열의 구성요소로 분해하는 실습 예제입니다. 우선 필요한 라이브러리부터 불러오고 데이터를 호출합니다.
이후 window 크기가 7일 (일주일), 30일 (1개월), 90일 (3개월) MA를 pandas의 rolling() 함수를 이용하여 구합니다. Window 크기가 짝수일 때는 center = True를 지정하여 centered MA로 계산합니다.
import yfinance as yf
import pandas as pd
import matplotlib.pyplot as plt
btc = yf.download("BTC-USD", start="2020-01-01")
sma7 = btc["Close"].rolling(window=7).mean()
sma30 = btc["Close"].rolling(window=30, center=True).mean()
sma90 = btc["Close"].rolling(window=90, center=True).mean()
df_sma = pd.concat([btc["Close"], sma7, sma30, sma90], axis=1)
df_sma.columns = ["Close", "SMA7", "SMA30", "SMA90"]
df_sma = df_sma.dropna()
BTC 데이터프레임
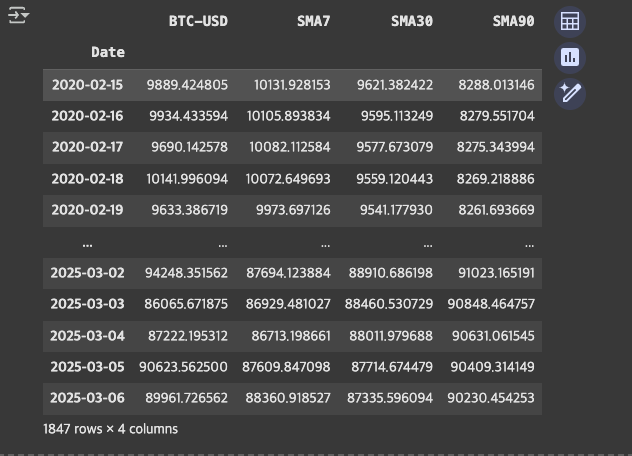
pandas rolling mean 결과
아래는 아래는 구한 3개의 moving average를 차트로 구현한 모습입니다. Moving average의 window 길이가 길수록 단기 불규칙성을 제거하여 부드러운 장기 추세선을 구해주고 있는걸 볼 수 있습니다.
s_date = "2020-02-15"
e_date = "2025-03-06"
fig, ax = plt.subplots(figsize=(16, 9))
ax.plot(df_sma.loc[s_date:e_date, :].index, df_sma.loc[s_date:e_date, "BTC-USD"], label="Price")
ax.plot(df_sma.loc[s_date:e_date, :].index, df_sma.loc[s_date:e_date, "SMA7"], label="SMA 7")
ax.plot(df_sma.loc[s_date:e_date, :].index, df_sma.loc[s_date:e_date, "SMA30"], label="SMA 30")
ax.plot(df_sma.loc[s_date:e_date, :].index, df_sma.loc[s_date:e_date, "SMA90"], label="SMA 90")
ax.legend(loc="best")
ax.set_title("BTC price & SMA7 & SMA30 & SMA90")
ax.set_ylabel("Price (USD)")
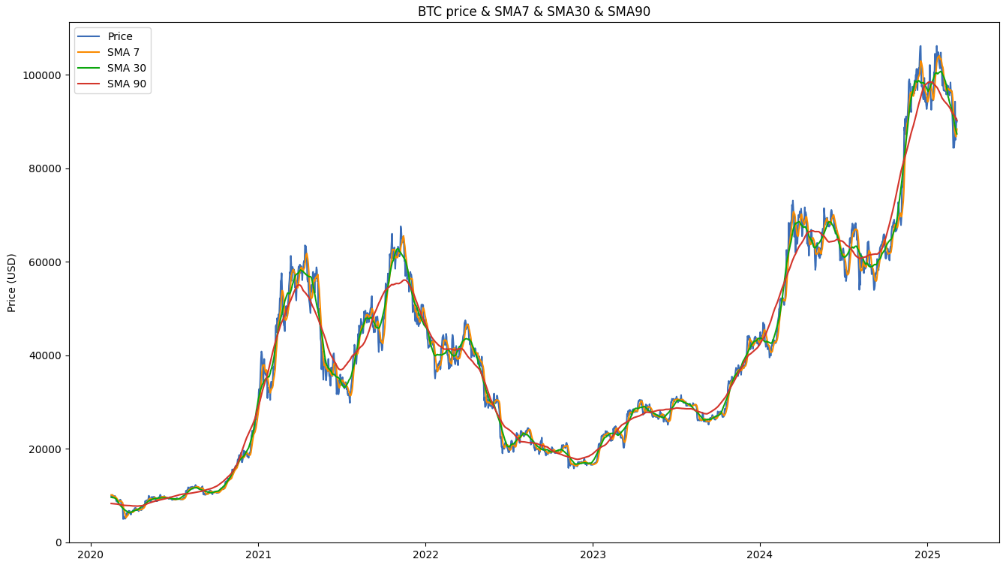
추세선 시각화
statsmodels로 시계열 분해
이제 statsmodels를 이요해서 시계열 분해를 하고자 합니다. seasonal_decompose() 함수에 분해할 시계열 데이터 model="additive" 또는 "multiplicative"를 지정하여 가법 또는 승법 seasonality를 지정합니다. period는 seasonality의 주기를 지정합니다. 예시에서는 1개월 = 30일 주기를 지정합니다. 성공적인 시계열 분해가 되기 위해서는 맨 아래의 그림에 나타난 잔차 (residual)이 가법모형인 경우 0을 중심으로 일정한 패턴이 없이 빠르게 진동해야 하고 승법모형의 경우 1을 중심으로 일정한 패턴이 없이 빠르게 진동해야 합니다.
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(btc["Close"]["2021-01-01":], model="additive", period=30)
result.plot()
plt.show()
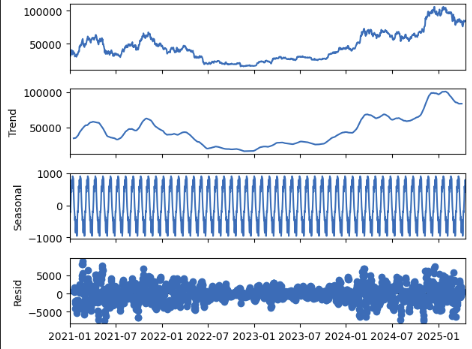
가법 (additive) 분해 예시
위 plot의 경우 추세와 계절성은 잘 분리되었고 잔차는 무작위 노이즈 (white noise)처럼 보이기 때문에 성공적인 분해라고 볼 수 있습니다.
아래는 seasonality를 승법으로 교체하고 period=30으로 진행한 결과입니다.
result = seasonal_decompose(btc["Close"]["2021-01-01":], model="multiplicative", period=30)
result.plot()
plt.show()
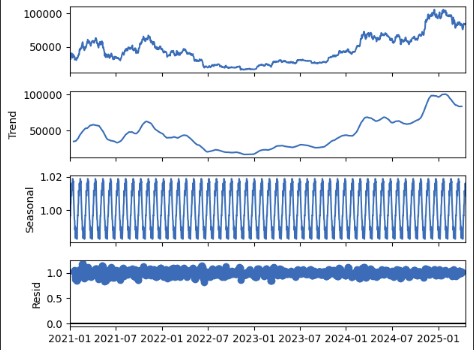
승법 (multiplicative) 분해
위의 결과도 잘 분해가 된 걸 볼 수 있습니다. 추세는 부드럽게 잘 분리되었고, 계절성은 주기적으로 안정되었으며 잔차는 랜덤하고 구조 없이 잘 흩어졌습니다.